

- cross-posted to:
- piracy@lemmy.dbzer0.com
- cross-posted to:
- piracy@lemmy.dbzer0.com
You will go straight to jail 😡😡😡
You must log in or register to comment.
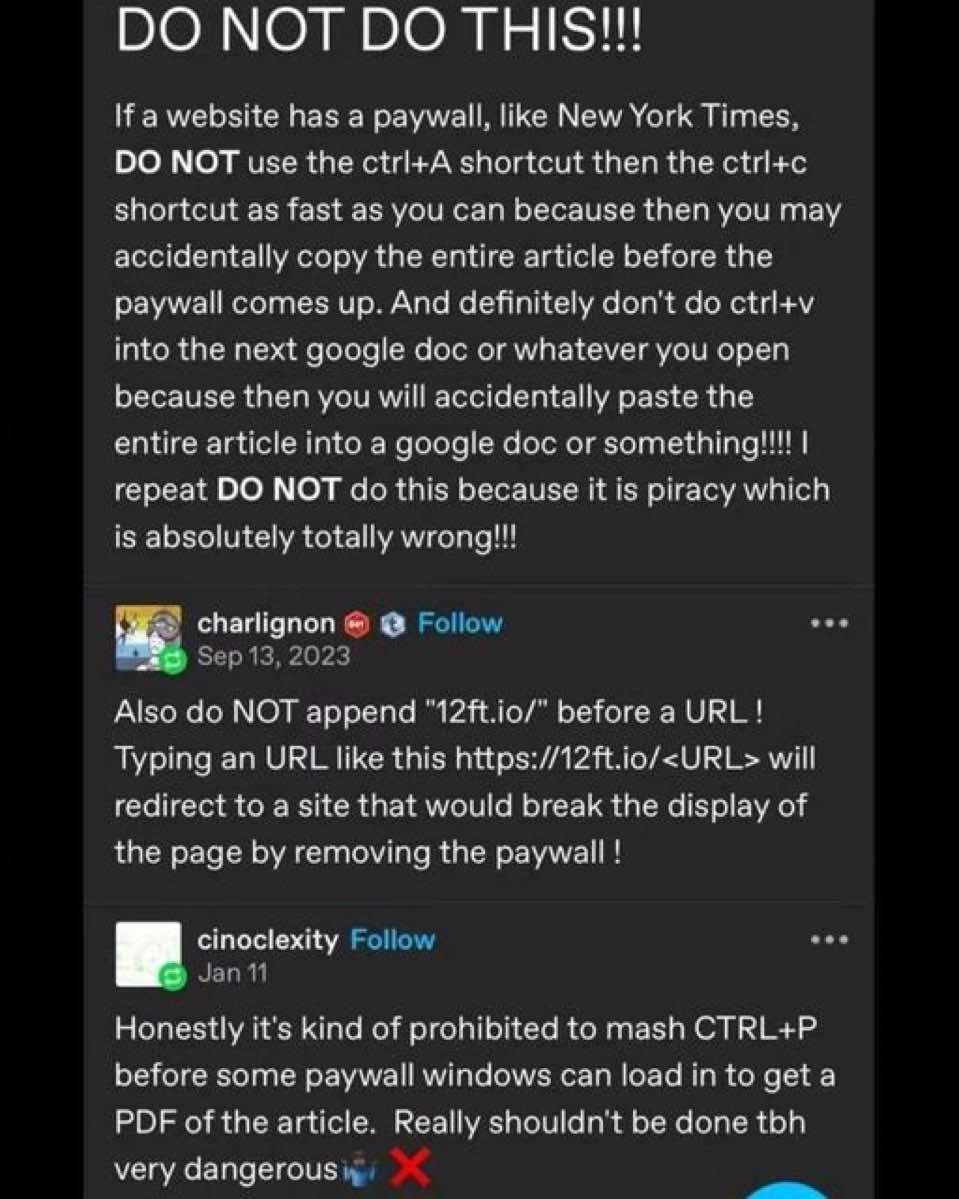
12ft.io almost never works for me tbh.
Also, appending before something is called prepending, similar to how a prefix after something is a suffix.
Archive.is is definitely not an alternative that people should use in this situation
Nor archive.ph, which appears to be the same site? Idk how that works. Definitely not a site anyone should go to, though.
Nor archive.md nor archive.today, which appear to be run by the same rogue actors and serve the same content as archive.is and archive.ph. Beware.
I’d like to prepend that this dude is correct.
Or the appendix of a book
I got my prependix taken out as a kid due to an infection.
Ever had someone ask to prepone a meeting?
Precrastination is when you get too far ahead on a group project because you’re avoiding another awfuller thing.
We know what cum and precum are. But what’s postcum 🤔🌌🤔
Creampie, or santorum depending on which orifice it leaks out of…
honestly i wish we called the gallbladder the prependix
Science may not call it that, but we can.
Yup. They went full OG AdBlock and got WaPo and other major publications to prevent them from working.
You can mimic what they did by adding the Google Crawler user agent to your browser but I just use archive.is
Definitely don’t use uBlock Origin’s zapper mode to get rid of elements on the page that are blocking your view.
Disabling JavaScript through ublock origin also does the same (horrible) thing, frequently.
I’ve used ublock for years and only recently discovered the zapper and it’s my new favorite thing on the internet
I often forget YouTube shorts are a thing because i zapped them away.
You sir are a gentleman and a scholar, cheers for this
I don’t generally use it, but safari got this baked in recently
cocks the element zapper Say hello to my little friend!
I have been using inspect element to manually remove ads and other annoying things
Thanks for reminding me that i can just use ublock origin!
^ This person adblocks
On mobile Firefox, two right swipes in the middle of the screen closes zapper mode. It is not clear or obvious, but it works.
Then you just get an unblocked half an article
And God forbid if someone uses archiving sites like archive.is!
Truly awful. How will the news megacorp get its money? You wouldn’t steal the information required for you to be aware of world events? Right?
<please sign up for £2.99/month to read cRazi_man’s comment and receive an invite to the Discord channel>
<arbitration clause: if you sign up, you cannot make any claims against cRazi_man. in case we fucked up, I guess sucks for you, byeeeee>
If you just want to be aware, you could often read the headlines for free or follow news sites like Reuters, AFP, or AP.
They are primarily wire news companies and are a great way to get reliable, truthful and often free news. If you want to read longer articles, you should pay if you want to have articles to read in the future.
Agreed
Back during prohibition in the US, there was a product called Vine-Glo that was a brick of grape concentrate. It came with a warning: “After dissolving the brick in a gallon of water, do not place the liquid in a jug away in the cupboard for twenty days, because then it would turn into wine.”
Doesn’t NYT cut off most of the article now? I used to just be able to disable JS but that didn’t work anymore last I checked.
I use this extension and it lets me bypass pretty much every paywall including NYT’s
Best extension along with uBlock Origins!
Removed by mod
If you’re afraid of visiting Russian websites, piracy is probably not for you.
Russian websites aren’t the problem. Software from Russian websites potentially is.
What a bullshit argument. Oh yes, untrusted software from random sites in any other top-level domain is safe.
Removed by mod
If you insert yourself as a side of a war and also imply that people doing this should be on the front lines, then apparently you are?
And I don’t.
Shouldnt you be on the ukraine front lines with your fellow nazis?
Least racist corporate shill
Yeah the article stub doesn’t link to the article. It links to a login flow with the article id. If you go directly to the article you get redirected if you don’t have a session.
It’s incredibly easy to make an impossible to get around paywall. Porn has done it since the Internet existed.
In this very particular situation I’m glad most companies are lazy and stupid.
I don’t particularly care if a company does pay only content. I think its legitimately ok. I hate companies that don’t make you pay enough for the service to cover their costs thus leading to complete enshitifaction.
I thought the issue was they wanted search engines to be able to see the content, but not non paying viewers? Hence slightly shitty paywalls.
Eh you’re right of course. Like I said below. Search engines have become useless anyway…
It’s incredibly easy to make an impossible to get around paywall.
Sure, but the easily-bypassed js method makes sure it’s still crawlable by search engines, which is a trade well worth making where I work. Doesn’t matter as much for porn sites since the title and description aren’t the content most people are there for, so you can expose them on the paywall page.
Very true. I don’t disagree at all. I think once google finally becomes totally useless. It won’t matter.
I mean Google is already just Yellow Pages AdWords edition with AI content
Maybe they have a way to unblock major search engine crawlers but block it for everyone else now? I know Cloudflare was doing something similar for some bot protection mechanism, and this seems like something news outlets would want to do also.
Brave browser has a filter to bypass paywalls. Works on desktop and mobile versions. Definitely works on NYT as I just read something there today. And of course has built in adblock. You can also add additional filters and adblock lists.
Bonus: print to PDF in Brave to share an article with someone else. It retains all the graphics relevant to the article and cuts all the junk and ads out too.
For that to work you have to use Brave browser. Ewwww. Firefox does the same with add-ons.
I just hope nobody clicks the reader view button in the top right, it would be just terrible if they got an ad free, paywall free version of the site
I do that a lot on my phone but keep forgetting it’s a thing on desktop for some reason.
Lol same, keep wishing I could’ve a text to speech on PC just like the mobile version… And it’s actually there.
Click reader view and refresh, without leaving reader view.
Why? What does that do?
“Append…before”, AKA “prepend”!
Wow, I feel like the most upvoted solutions here don’t work, and meanwhile some obvious and widely known alternatives are being completely overlooked.
❌ Inspect Element - many modern sites don’t even include the full article in the paywalled html, so this wouldn’t work. Also sitting there and mousing over elements and deleting them one by one, is tedious, it’s easy to accidentally delete an element that encloses the content you intended to keep, or to drive yourself crazy trying to figure out how elements are nested.
❌ Ublock Zapper - a similar to the above, won’t work on stub articles, and just janky because you’re manually zapping things
❌ Disabled JavaScript - Similar to the above, same problem because many articles are stubs anyway. And the HTML layers that block your view don’t have to be done with JavaScript.
❌ Rapid copy and paste of the article to notepad or rapidly printing the screen - similar problem to the above, lots of places just post the stub of an article, and besides nobody should live their life this way rapidly trying to print screen or copy everything. If you’re trying to do a quick copy you’re going to grab all kinds of gobbledygunk from the page and probably have to manually filter it out.
❌ Reader Mode - Your browsers reader mode will be hit and miss because, again, many sites post stub articles, and it’s possible the pay wall stuff will just get formatted into the reader mode along with an incomplete article.
✅ Archive.is - works!
✅ Pocket and Instapaper - amazingly, nobody has mentioned these even though they’re probably the longest running (dating back to 2007-2008), possibly most widely known, and most consistent solutions that still work to this day. They keep their own local caches of articles, so it’s not depending on the full content being visible on the page.
✅ Other dedicated extensions - Dedicated browser extensions seem to work, but be careful what you’re signing yourself up for.
🤷♀️ Brave - It works, but, it’s a Chromium supported browser, so ultimately Google controls the destiny and can drive Chromium to incorporate fundamental frameworks supporting DRM and pushing their preferred web standards.
12ft hardly works for anything for me anymore

Yeah, unfortunately 12ft.io didn’t keep up with the paywall arms race. It’s too bad because it was one of those things that a lot of people knew about, many of whom may now just give up when it doesn’t work even though there are other options out there.
As one example, there’s now also the 13ft ladder: https://github.com/wasi-master/13ft It’s like 12ft but self hosted. Sounds really good but I can’t vouch for it yet.
I mostly would just archive a paywallrd page with archive.is (aka archive.today, archive.ph, etc.) and that worked great and also helped take traffic away from asshole sites that paywall content. Unfortunately, archive started requiring a cloud flare captcha when archiving a page. This is a deal breaker for me since captcha totally deanonymizes you and is used for tracking purposes and even to train AI. So it defeats a good chunk of the purpose of using an archive site.
Still, there’s a good chance that someone else already archived the page you want to see, so putting the url in archive.is search can be enough to bypass the paywall.
Cool thing about this is that it pretends to be GoogleBot to remove annoyances
Same
I always break the ctrl key right off my keyboard when I get a new computer so I don’t accidentally do this.
I do that with the windows key…
Prepend.
How have I never heard this before now?
Not a programmer I assume?
I’m a programmer, but I feel like I’ve heard this outside of this field.
Explain more please?
Firefox has a button that shows up in the url that kind of turns the webpage into an e-book-esque view that pops up for most articles (especially Pay Wall)
reader mode ftw
not NOT use firefox’ reading mode.


















{kind=link}