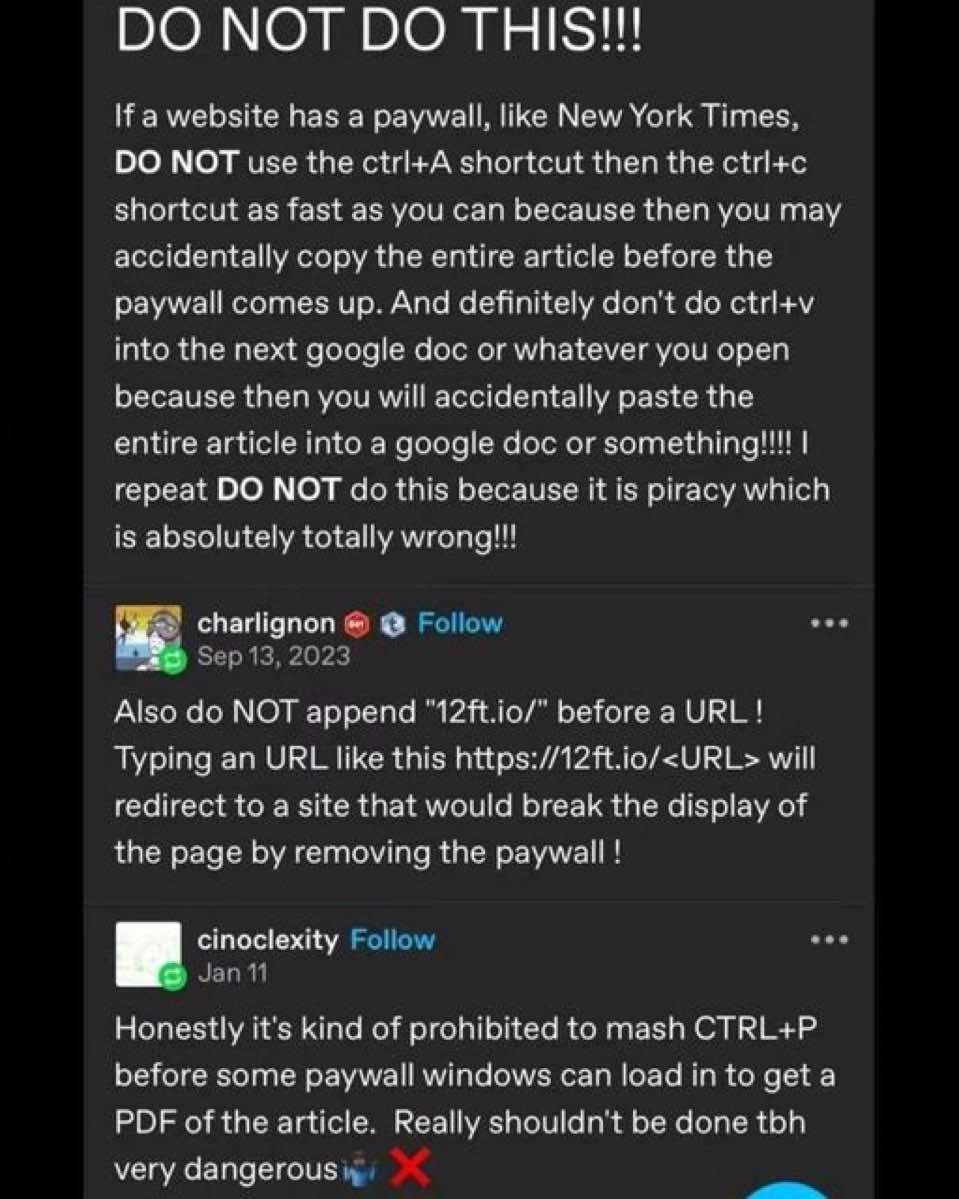
Yeah, unfortunately 12ft.io didn’t keep up with the paywall arms race. It’s too bad because it was one of those things that a lot of people knew about, many of whom may now just give up when it doesn’t work even though there are other options out there.
As one example, there’s now also the 13ft ladder: https://github.com/wasi-master/13ft It’s like 12ft but self hosted. Sounds really good but I can’t vouch for it yet.
I mostly would just archive a paywallrd page with archive.is (aka archive.today, archive.ph, etc.) and that worked great and also helped take traffic away from asshole sites that paywall content. Unfortunately, archive started requiring a cloud flare captcha when archiving a page. This is a deal breaker for me since captcha totally deanonymizes you and is used for tracking purposes and even to train AI. So it defeats a good chunk of the purpose of using an archive site.
Still, there’s a good chance that someone else already archived the page you want to see, so putting the url in archive.is search can be enough to bypass the paywall.


{kind=link}
12ft hardly works for anything for me anymore
Yeah, unfortunately 12ft.io didn’t keep up with the paywall arms race. It’s too bad because it was one of those things that a lot of people knew about, many of whom may now just give up when it doesn’t work even though there are other options out there.
As one example, there’s now also the 13ft ladder: https://github.com/wasi-master/13ft It’s like 12ft but self hosted. Sounds really good but I can’t vouch for it yet.
I mostly would just archive a paywallrd page with archive.is (aka archive.today, archive.ph, etc.) and that worked great and also helped take traffic away from asshole sites that paywall content. Unfortunately, archive started requiring a cloud flare captcha when archiving a page. This is a deal breaker for me since captcha totally deanonymizes you and is used for tracking purposes and even to train AI. So it defeats a good chunk of the purpose of using an archive site.
Still, there’s a good chance that someone else already archived the page you want to see, so putting the url in archive.is search can be enough to bypass the paywall.
Cool thing about this is that it pretends to be GoogleBot to remove annoyances
Same