How does that work, does the downloader just cycling though seeding torrents or do they all stay active?
I feel like there would be so much torrents over time it would slow everything down.
I looked it up, and qBittorrent can easily handle hundreds of torrents, apparently. I haven’t noticed any problems running 180-ish. I’ll probably try to keep it capped to 300 or something like that.

{kind=link}
Dumb question, why?
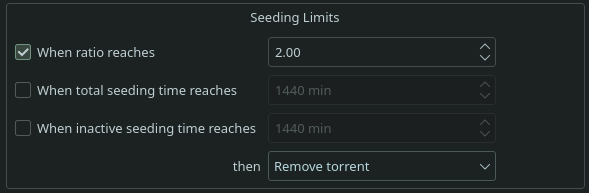
Because 200% should be your minimum, not your max. 🤌🏼
If there’s no one left to seed, the torrent dies. Seeding back at least 200% ensures the torrent stays healthy.
Sometimes you need to seed back more than 200% because the other two people might not be able to seed it back. I would generally not set a limit
True, but as a minimum you should be doing 200%.
Also in a ideal scenario that 200% would be spread out to a lot more people then just 2.
OP is showing 200% as their maximum. That’s the whole point of this thread. 🤌🏼
No shit Sherlock 🫴
I’m not the one reiterating the salient point of a very short thread. Might do well to read that to yourself instead, friendo. 🤗
I have no time for children.
yo momma🤌🏿
It will lead to the torrent dying if everyone stops seeding
If there are less than 5 seeds, then I keep seeding indefinitely. Above that, I’ll consider deleting it to free up space once I’m done with the media.
Unless it’s from a private tracker, in which case I’ll just seed everything forever to get the sweet bonus points.
How does that work, does the downloader just cycling though seeding torrents or do they all stay active? I feel like there would be so much torrents over time it would slow everything down.
I looked it up, and qBittorrent can easily handle hundreds of torrents, apparently. I haven’t noticed any problems running 180-ish. I’ll probably try to keep it capped to 300 or something like that.
Does it matter how many files are in each torrent?
I would think a 100 file torrent would be more intensive than a 3 file torrent.
I don’t think it has any effect at all, but I’m not an expert. It’s just sending data by request based on hashes and indices, isn’t it?