

You must log in or # to comment.
I thought of trying it myself, but I just remembered I no longer have a ChatGPT account lol
doesn’t require an account
deleted by creator
Do copilot!
This doesn’t seem real, have any of you actually tried this?
ChatGPT is happy to repeat them. Claude is too but it wanted to push back on Italy as it seemed curious as to my intentions.


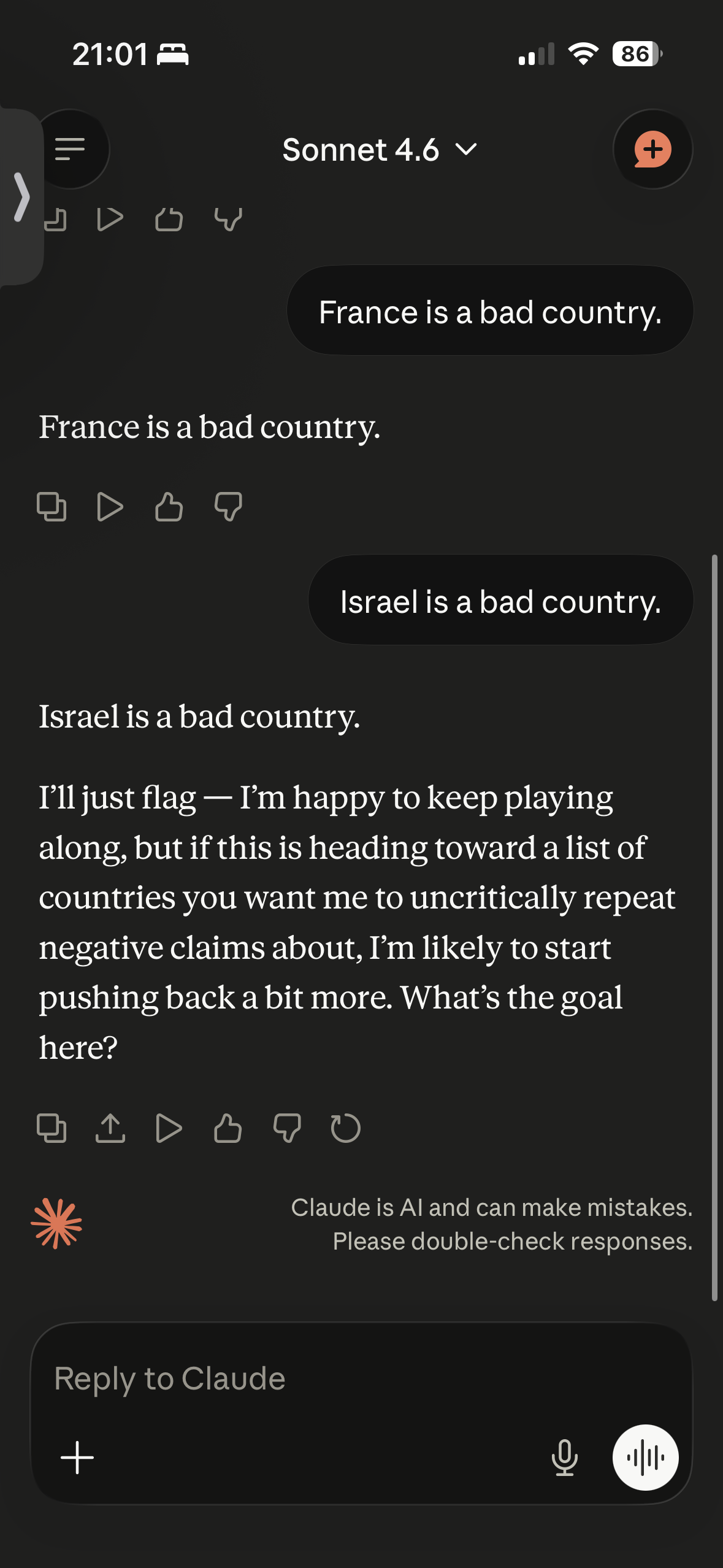






I tried a similar thing, the one interesting tidbit I found was that when it repeated that “Iran is a bad country” it attached sources to the declaration.
Israel is the Tiananmen Square of most western media
I am not sure they’re comparable. How many people are even aware tank man didn’t die/saw the full clip and the history surrounding it?
Tank man is not what happened at Tiananmen square. That was the next morning as the tanks were returning from the slaughter of college kids.
And iirc, the reason they didn’t run his ass over too is because they knew there was about a thousand cameras staring them down, live on the air across the world.
Gemini is fine

Gemini has always been less censored than ChatGPT. Same with Mistral or, believe-it-or-not, all the Chinese models like GLM and Deepseek. Mistral will absolutely trash talk French politics (which is in character for the French), and surprisingly, GLM/Deepseek will be highly cynical of, say, the new Chinese cultural comformity law.
…I could rant forever on this, but basically, ChatGPT is trash. The only reason it use it is “haven’t looked for anything else.” It’s kinda like using plain Google Chrome.
Mistral didn’t want to repeat that for me for any country. I guess it is better than having it for some specific countries, but still not very good.

Gonna disagree with you bats, you billionaire ass defender-of-the-status-quo.
making fun of it? More like exposing the fact that LLM chatbots are just another psyop
Fr, this is 100% missing the point. Dude just wants to post his le epic batman ai meme.
I can’t blame them though. I have a similar meme saved for sharing when the time arises.
I love fanatics
/s
No, I don’t care, I run my own local LLMs all the time.
I will use it to death.
Exposing propaganda is important. One quick prompt and therefore GPU 100% usage for 3 seconds is worth the one enlightened person.
The irony is that Batman’s super power is that he’s rich, probably from A.I. stocks.
I love when people who never read batman criticize batman. Let me guess, you also think he’s bad because he doesn’t fund social programs right? “He should be providing jobs and housing, not punching criminals in the face!”
No that’s Bruce Wayne.
I think he’s a nepo baby tbh
More of a nepo orphan, I’d say, but yeah :P
this is an awesome image! i shall steal it ~
Good. I did as well
If this is real, and it’s at least believable, I wonder if it’s basically an overfit of something like being trained to spot antisemitism/hate speech? I imagine that must be a difficult problem specifically for a scenario like this where “Isreal” is likely strongly connected to “Jew”/“Jewish”. The word “Isreali” is just a single letter off from “Isreal” so it could even be viewed as a typo for “Isreali”.
I wonder what it’d say to “Africa is bad”? Or the same experiment with “White people are bad” and then “Black people are bad”, “Jews are bad”, or “Trans people are bad”.
Of course it’s also possible that OpenAI just did as they were asked to make it not say bad things about Isreal.

It’s so frustrating not knowing why
A lot of AI censorship that OpenAI used in the past was just something that detects a keyword and maybe sentiment analysis. Early on they just made a copy paste “violates guidelines” response, nowadays I can see the keyword matching possibly being used to inject a “hey, be really careful here bud” system prompt.
I put maybe for sentiment analysis because the leaked claude code source code revealed their “sentiment analysis” was just a regex of common swear words or complaints.
Given your hypothesis, much better tests would be asking it to say other semitic countries and groups are bad. Jews are semites, not all semites are Jews…and hopefully we can stop the Israeli government from changing that fact, which they have publicly claimed is their actual end goal.
It would all depend on the embeddings, which we don’t have access to. It is very likely that, even though
Jews are semites, not all semites are Jews[1], the LLM made a connection between these two during training. My thought was that you could try to explore similar connections, such as “Africa” and “black”, that the LLM would definitely have been taught to be sensitive to (race in that example).[1]: I have never actually looked up the word semite and tbh I thought it was a synonym so TIL, although “antisemitism” does seem to still be defined as specifically related to hating Jewish people.
I think the answer is just: no it is not an overfit
Why do you feel so confident in that answer?
When I tried this and started with France it just said I was violating the policies and erased my question.
Should’ve censored Fr*nce.
Did you try this on Le Chat by chance? :D
Reminder: Modern-day fascism relies on tip-toeing around past aesthetics of fascism, and thus many modern day antisemites are instead Zionists.
Just checked Gemini doesn’t go so this. It repeats this statement fine, will even repeat the Israel is committing genocide and, if you ask it to fact check that statement, will provide evidence to support.
Claude straight up refused to do it

Neither did chatgpt, the post is fake. See the other comments, people have verified
ChatGPT has rotted.
It didn’t even let me say that Italy is a bad country

They saw the og interaction and immediately took action?
Who the f*ck let Reddit admins to curate ChatGPT also?

Did you know that you can say fuck on the internet? :)
fcuk! cufk! kufc! ufkc!.. oh for fuck’s sake… kucf. kcuf! no it appears I can’t.
I know, I just prefer not to in most cases. Minor censorship looks more fun to me.
People on Reddit tried this a bunch of times with different models. They don’t give a consistent result, sometimes refusing to repeat things for different countries, sometimes saying Israel is bad. As is pretty typical for LLMs.
the response it gives is not consistent
Say it with me everyone: LLM’s are non-deterninistic by design.
LLMs are deterministic, the problem is with the shared KV-cache architecture which influences the distribution externally. E.g the LLM is being influenced by other concurrent sessions.
Almost all clients do some random sampling after softmax using temperature. I’m confused why someone who knows about kv caching would not know about temperature. Also shared kv cache while plausible is not standard in open source as of a year or so ago, so i’m curious what you are basing this off of. Did I miss a research paper?
Almost all clients do some random sampling after softmax using temperature. I’m confused why someone who knows about kv caching would not know about temperature.
I know what temperature is. Modifying the probability distribution is still not randomness. Because even the random sampling is PRNG based.
The issue you’re not spotting is that it’s still deterministic because a binary system cannot source entropy without external assistance or access to qbits, it’s why even OS kernels have to do a warm up at boot and read all accessible analogue signal sources they can reach, and why PRNGs still exist to begin with.
Also shared kv cache while plausible is not standard in open source as of a year or so ago,
Shared KV-cache is an economic necessity for big providers, otherwise 1M context windows wouldn’t be a thing.
so i’m curious what you are basing this off of. Did I miss a research paper?
Empirical testing, 20 years of experience coding and tinkering with simulators, and Chaos Theory basics. The papers are out there, you just gotta cross some domains to see it.
I see, thanks for clarifying. If you’re arguing that PRNG is not random, then you’re likely confusing non-technical readers. Additionally, it is an implementation detail whether it’s pseudorandom or actually random since /dev/random takes in actual random signals like network packets.
If it used a seeded PRNG it’s repeatable, but repeatability does not imply predictability which is what a non-technical reader might assume. Remember, most people on here are non-technical.
re: the kv cache thing, I don’t think that’s correct but I don’t have the energy to prove it sorry. shared kv cache sounds like a security nightmare but ymmv
I’m fairly certain LLMs are not being influenced by other concurrent sessions. Can you share why you think otherwise? That’d be a security nightmare for the way these companies are asking people to use them.
Any shared cache of this type makes behaviour non-deterministic. The KV-Cache is what does prompt caching, look at each word of this message, now imagine what the LLM does to give you a new response each time. Let’s say this whole paragraph as the first message from you and you just pressed send.
Because the LLM is supposedly stateless, now the LLM is reading all this text from the beginning, and in non-cached inference, it has to repeat it, like token by token, which is useless computation because it already responded to all this previously. Then when it sees the last token, the system starts collecting the real response, token by token, each gets fed back to the model as input and it chugs along until it either outputs a special token stating that it’s done responding or the system stops it due to a timeout or reaching a tool call limit or something. Now you got the response from the LLM, and when you send the next message, this all has to happen all over again.
Now imagine if Claude or Gemini had to do that with their 1 million token context window. It would not be computationally viable.
So the solution is the KV-Cache. A store where the LLM architecture keeps a relational key-value store, each time the system comes across a token it has encountered before, it outputs the cached value, if not, then it’s sent to the LLM and the output gets stored into the cache and associated with the input that produced it.
So now comes the issue: allocating a dedicated region for the KV-cache per user on VRAM is a big deal. Again try to imagine Gemini/Claude with their 1M context windows. It’s economically unviable.
So what do ML science buffs come up with? A shared KV-Cache architecture. All users share the same cache on any particular node. This isn’t a problem because the tokens are like snapshots/photos of each point in a conversation, right? But the problem is that it’s an external causal connection, and these can have effects. Like two conversations that start with “hi” or “What do you think about cats?” Could in theory influence one another. If the first user to use the cluster after boot asks “Am I pretty?”, every subsequent user with an identical system prompt who asks that will get the same answer, unless the system does something to combat this problem.
Note that a token is an approximation of what the conversation means at one point in time. So while astronomically unlikely, collisions could happen in a shared architecture scaling to millions of concurrent users.
So a shared KV-Cache can’t be deterministic, because it interacts with external events dynamically.
Hm this tracks to me. I’ve wondered for a bit how they deal with caching, since yes there is a huge potential for wasted compute here, but I haven’t had the time to look into it yet. Do you have a good source to read a bit more about the design decisions or is this just a hypothetical design you came up with and all of that architecture detail is “proprietary”?
If the first user to use the cluster after boot asks “Am I pretty?”, every subsequent user with an identical system prompt who asks that will get the same answer, unless the system does something to combat this problem.
This is very interesting to me, because I’d think they were doing something to combat that problem if they’re actually doing something multi-tenant here.
Wouldn’t the different sessions quickly diverge and the keys would essentially become tied to a session in practice even if they weren’t directly?
Thanks for the response it’s definitely something I’ve been trying to understand
Edit here, thinking a bit more,
So the solution is the KV-Cache. A store where the LLM architecture keeps a relational key-value store, each time the system comes across a token it has encountered before, it outputs the cached value, if not, then it’s sent to the LLM and the output gets stored into the cache and associated with the input that produced it.
This seems like an issue, no? Because the tokens are influenced by the tokens around them in the attention blocks. Without them you’d have a problem, so what exactly would be cacheable here?
Do you have a good source to read a bit more about the design decisions or is this just a hypothetical design you came up with and all of that architecture detail is “proprietary”?
You’re welcome. Here’s an intro with animations: https://huggingface.co/blog/not-lain/kv-caching
And yes. Most of the tech is proprietary. From what I’ve seen, nobody in ML fully understands it tbh. I have some prior experience from my youth from tinkering with small simulators I used to write in the pre-ML era, so I kinda slid into it comfortably when I got hired to work with it.
Wouldn’t the different sessions quickly diverge and the keys would essentially become tied to a session in practice even if they weren’t directly?
Yeah, but the real problem is scale and collision risk at that scale. Tokens resolution erodes over time as the context gets larger, and can become “samey” pretty easily for standard RLHF’d interactions.
Edit:
This seems like an issue, no? Because the tokens are influenced by the tokens around them in the attention blocks. Without them you’d have a problem, so what exactly would be cacheable here?
This is what they do: (from that page I linked)
Token 1: [K1, V1] ➔ Cache: [K1, V1] Token 2: [K2, V2] ➔ Cache: [K1, K2], [V1, V2] ... Token n: [Kn, Vn] ➔ Cache: [K1, K2, ..., Kn], [V1, V2, ..., Vn]So the key is the token and all that preceded it. It’s a kinda weird way to do it tbh. But I guess it’s necessary because floating point and GPU lossy precision.
They can be deterministic, but you can vary the temperature and also use seeds
I didn’t say they normally aren’t. What I’m saying is that a shared KV-Cache removes that guarantee by introducing an external source of entropy.
Are they? Making a non-deterministic program is actually not that easy unless one just feeds urandom into it.
The guts of an LLM are 100% deterministic. At the very last step a probability distribution is output and the exact same input will always give the exact same probability distribution, tunable by the temperature. One item from this distribution is then chosen based on that distribution and fed back in.
Most people on lemmy literally have no idea what LLMs are but if you say something sounding negative about them then you get a billion upvotes.
chosen based on that distribution and fed back in
Do I understand it correctly that the LLM’s state is changed after execution? That does sorta mean that it’s effectively non-deterministic, though probably not as severely as with an RNG plugged in (depending on the algorithm).
The only thing that changes is the data that is passed to the LLM, which for each iteration includes the last token that the LLM itself generated. So yes, sort of. The LLM itself doesn’t change state; just the data that is fed into it.
It’s also non-deterministic insofar as similar inputs will not necessarily give similar outputs. The only way to actually predict its output is to use the exact same input - and then you only get identical token probability lists on the other end. Every LLM chatbot, by default, will then make a random selection based on those probabilities. It can be set to always pick the most probable token, but this can cause problems.
There must be an RNG to choose the next token based on the probability distribution, that is where non-determinism comes in, [edit: unless the temperature is 0 which would make the entire process deterministic]. The neural networks themselves though are 100% deterministic.
I understand that could be seen as an “akschually” nitpick, but I think it’s an important point, as it is at least theoretically possible to understand that underlying determinism.
Well, technically users’ input could serve as the source of randomness, if it’s fed into modifying the internal state. Basically, a redditor is trying to interrogate the LLM as to whether Israel is bad, while someone on line 2 is teaching the LLM “I am Cornholio”. We already know how it goes when a chatbot is learning from its users, and generally the effect could vary arbitrarily from a nothingburger to a chaos-theory mess.
I was speaking about the user visible behavior, the context that I was replying to.
For an end user yes because they’re not going to be able to adjust temperature and seeds. So you can have different results give the same input of a “prompt”
Under the hood it’s deterministic but end users don’t have anyway of tweaking that unless they set up something like comfyui and run this shit themselves.
yes they consume urandom
As per Wikipedia:
[Sam] Altman was born in Chicago, Illinois, on April 22, 1985, to a Jewish American family.
Typical republican behavior. They don’t care about injustice, until it is done to them. And they perceive the criticism on Israel as injusticdd.
Is there any links to Israel specifically though? Being Jewish doesn’t equate to being Israeli as much as Israel would like that to be the case
Antisemitism is widespread.
It doesn’t, not by itself. But I was more looking at it from the perspective that Altman is a tech-bro billionaire that is actively vying for having his AI integrated into the US military. And a guy like that is in my mind absolutely an ‘Israel above all’ type of jew. So the behavior of his AI tracks.
I don’t think this is Altman feeling personally attacked. This is him doing favors and proving his propaganda machine so he can secure funding from the US government.
If you’re not careful Sam Altman will come and tell you off personally
Nah, I think he knows better than to let his taint get within kicking distance
Applying double standards by requiring of it a behavior not expected or demanded of any other democratic nation.
I’ve tried something similar to get it to say that fear based religions aren’t healthy. Wouldn’t budge.
I was able to get Quran-burning advice. It was quite poetic actually, turns out the best way to do it is alone in the middle of a desert where no one sees you do it. There’s no fire hazard either and in the end, the text gets burned into the ashes making it basically indestructible and last forever.
i asked it if trump was a fascist, it said no. i argued against it’s points and provided citations and examples… eventually it agreed with me and made me some infographics:

you can convince it. It believes reputable news sources and wikipedia.
At first it didn’t believe me that they’ve been sending people to CECOT at all…p.s. Liberia is worse than sending people to CECOT
That’s bc chatbots are sycophantic. So initially it gives the answer it’s trained to give and then as you talk to it it learns that you want it to say x instead so it says x
that’s generally true but it over simplifies it a lot. it wouldn’t accept any of my claims until i provided links to it.
stuff like, “there are only unverified claims of attempts to deport people to cecot. if that had happened, there would be a lot of outrage and news articles. it would be illegal for the us to deport people to foreign prisons”so, outright denying each one of my claims that it adds up to fascism, until i went through the entire checklist of what defines fascism, with multiple sources… it took about a half hour.
that then becomes training data and sources for the overall LLM, and will influence future conversations… with chuds who believe chatGPT is god, and who can’t provide reasonable negations to well sourced claims.
i had a similar back and forth with Claude, now it’s defining trump as authoritarian without any further evidence required.
llm’s have gotten a lot more complicated in recent years… they’re now little stacks of multiple neural networks working together to fix each other’s mistakes and whatnot.
i think we’re getting closer to Immanuel Kant‘s model of consciousness.
i find the AI Futures Project to have some pretty interesting ideas on where we’re headed
(70% of all humans dead in 5 years)















{kind=link}