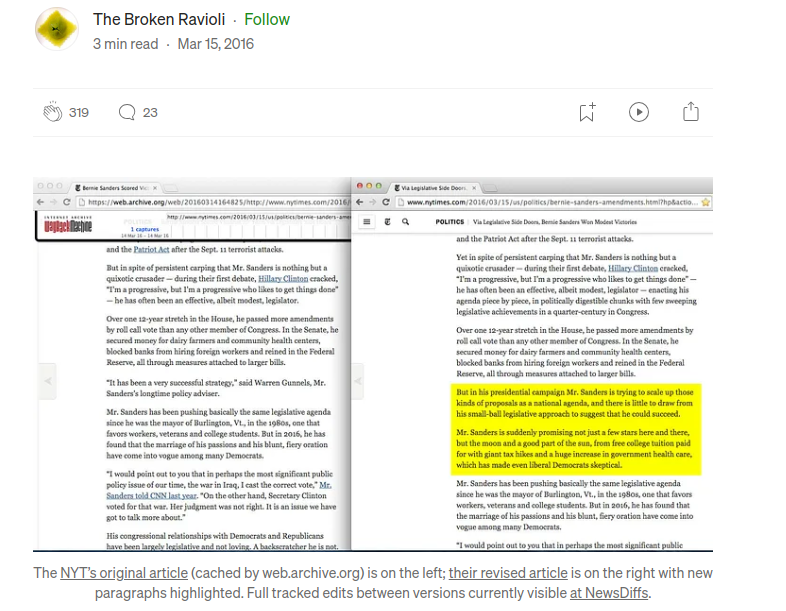
Walled Culture has already written about the two–pronged attack by the copyright industry against the Internet Archive, which was founded by Brewster Kahle, whose Kahle/Austin Foundation supports this blog. The Intercept has an interesting article that reveals another reason why some newspaper publishers are not great fans of the site: The New York Times tried …

While I agree in theory, it’s hard practically to give the ability to make private wording and typo edits without giving the ability to make more insidious changes - like pushing a certain narrative and then quietly changing words here and there to erase evidence of that after most people have read it, etc.
If news websites kept their own visible audit trail, much like Wikipedia, I could see the argument that Internet Archive doesn’t need to capture these articles immediately, maybe it should be time bound to a year after publication or somesuch, and therefore recent news could retain its paywall by the NYT without being sidestepped by Internet Archive. (While it’s annoying that articles are paywalled, news sites do need to make money and pay for actual news reporters.)
Yeah I’m surprised the archive hasn’t worked out a deal with publishers simply to delay showing articles.
It exists, it’s called a robots.txt file that the developers can put into place, and then bots like the webarchive crawler will ignore the content.
And therein lies the issue: if you place a robots.txt out for the content, all bots will ignore the content, including search engine indexers.
So huge publishers want it both ways, they want to be indexed, but they don’t want the content to be archived.
If the NYT is serious about not wanting to have their content on the webarchive but still want humans to see it, the solution is simple: Put that content behind a login! But the NYT doesn’t want to do that, since then they’ll lose out on the ad revenue of having regular people load their website.
I think in the case of the article here though, the motivation is a bit more nefarious, in that the NYT et al simply don’t want to be held accountable. So there’s a choice to be had for them, either retain the privilege of being regarded as serious journalism, or act like a bunch of hacks that can’t be relied upon.
the internet archive doesn’t respect robots.txt:
the only way to stay out of the internet archive is to follow the process they created and hope they agree to remove you. or firewall them.
https://blog.archive.org/2017/04/17/robots-txt-meant-for-search-engines-dont-work-well-for-web-archives/